ESWC Challenges
ESWC Challenges scheduled date: Tuesday, May 31th, 2016, 11:00 - 16.45
Session chairs: Anna Tordai, Stefan Dietze
This is the third edition of the ESWC Challenges track (previously called Semantic Web Evaluation). There will be five challenges presented this year which aim at assessing the state of the art systems and underlying methods in Semantic Web-related fields. The challenge task descriptions, evaluation results, datasets and participating system descriptions will be published as a volume of the Communications in Computer and Information Science (CCIS). In this track the challenge chairs will present the challenge tasks and datasets along with the results of the evaluations. For some of the challenges, participants will briefly present their systems and results. The competing contributions will be presented as posters and demos on Tuesday, June 2, 2016, in the morning session between 9am and 11am while winning applications will be announced and awarded during the ESWC closing ceremony on June 4.
Program
Accepted Papers
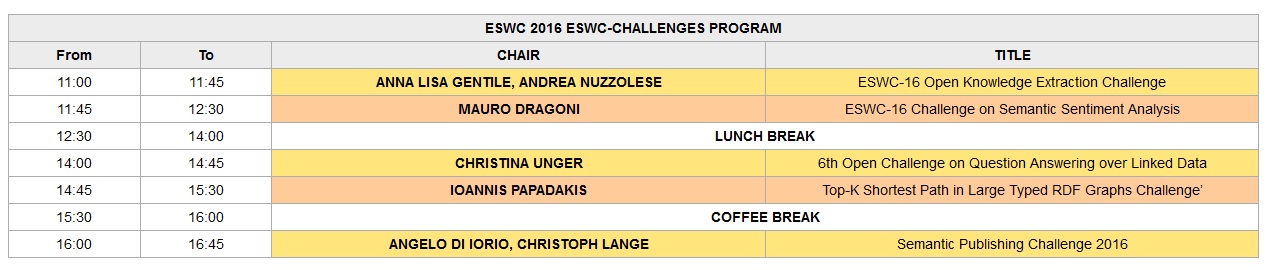
ESWC-16 Open Knowledge Extraction Challenge
- Julien Plu, Giuseppe Rizzo and Raphaël Troncy: Enhancing Entity Linking by Combining Models (Task 1)
- Mohamed Chabchoub, Michel Gagnon and Amal Zouaq: Collective disambiguation and Semantic Annotation for Entity Linking and Typing (Task 1)
- Stefano Faralli and Simone Paolo Ponzetto: Open Knowledge Extraction Challenge (2016): A Hearst-like Pattern-Based approach to Hypernym Extraction and Class Induction (Task 2)
- Lara Haidar-Ahmad, Ludovic Font, Amal Zouaq and Michel Gagnon: Entity Typing and Linking using SPARQL Patterns and DBpedia (Task 2)
ESWC-16 Challenge on Semantic Sentiment Analysis
- Emanuele Di Rosa and Alberto Durante: App2Check/Tweet2Check extension for Sentiment Analysis of Amazon Products Reviews (Task 1)
- Efstratios Sygkounas, Xianglei Li, Giuseppe Rizzo and Raphaël Troncy: The SentiME System at the SSA Challenge Task 1 (Task 1)
- Andi Rexha and Roman Kern: Exploiting Clauses for Opinion Mining (Task 1)
- Giulio Petrucci and Mauro Dragoni: An Information Retrieval-based System For Multi-Domain Sentiment Analysis (Task 1)
- Marco Federici and Mauro Dragoni: A Knowledge-based Approach For Aspect-Based Opinion Mining (Task 2)
- Soufian Jebbara and Philipp Cimiano: Aspect-Based Sentiment Analysis Using a Two-Step Neural Network Architecture (Task 2)
6th Open Challenge on Question Answering over Linked Data (QALD-6)
- Amir Pouran-ebn-veyseh: Cross-Lingual Question Answering Using Profile HMM & Unified Semantic Space (Task 1)
- Maurizio Atzori, Giuseppe Massimo Mazzeo and Carlo Zaniolo: QA3@QALD-6: Statistical Question Answering over RDF Cubes (Task 2)
Top-K Shortest Path in Large Typed RDF Graphs Challenge
- Sven Hertling, Markus Schröder, Christian Jilek and Andreas Dengel: Top-k Shortest Paths in Directed, Labeled Multigraphs
- Zohaib Hassan, Mohammad Abdul Qadir,Muhammad Arshad Islam, Umer Shahzad and Nadeem Akhter: Modified MinG Algorithm to Find Top-K Shortest Paths from large RDF Graphs
- Laurens De Vocht, Ruben Verborgh, Erik Mannens and Rik Van de Walle: Using Triple Pattern Fragments To Enable Streaming of Top-k Shortest Paths via the Web
Semantic Publishing Challenge 2016
- Stefan Klampfl and Roman Kern: Reconstructing the Logical Structure of a Scientific Publication using Machine Learning
- Sree Harsha Ramesh, Arnab Dhar, Raveena R. Kumar, Anjaly V, Sarath K. S, Jason Pearce and Krishna R. Sundaresan: Automatically Identify and Label Sections in Scientific Journals using Conditional Random Fields
- Andrea Nuzzolese, Silvio Peroni and Diego Reforgiato Recupero: ACM: Article Content Miner
- Riaz Ahmad, Muhammad Tanvir Afzal and Muhammad Abdul Qadir: Information Extraction from PDF Sources based on Rule-based System using Integrated Formats
- Bahar Sateli and René Witte: An Automatic Workflow for Formalization of Scholarly Articles' Structural and Semantic Elements
ESWC-16 Open Knowledge Extraction Challenge
The OKE challenge, launched as first edition at last year Extended Semantic Web Conference, ESWC2015, has the ambition to provide a reference framework for research on Knowledge Extraction from text for the Semantic Web by re-defining a number of tasks (typically from information and knowledge extraction), taking into account specific SW requirements.
The OKE challenge defines three tasks: (1)Entity Recognition, Linking and Typing for Knowledge Base population; (2) Class Induction and entity typing for Vocabulary and Knowledge Base enrichment; (3) Web-scale Knowledge Extraction by Exploiting Structured Annotation.
Task 1 consists of identifying Entities in a sentence and create an OWL individual representing it, link to a reference KB (DBpedia) when possible and assigning a type to such individual.
Task 2 consists in producing rdf:type statements, given definition texts. The participants will be given a dataset of sentences, each defining an entity (known a priori).
Task 3 will be based on one of the largest, publicly available collections of triples extracted from HTML pages (provided by the Web Data Commons project). Participants will use annotated Web pages as stimuli for training a Web-scale extraction system which is capable of extracting structured data from non-annotated pages.
Website: https://github.com/anuzzolese/oke-challenge-2016
ESWC-16 Challenge on Semantic Sentiment Analysis
Social media evolution has given users one important opportunity for expressing their thoughts and opinions online. The information thus produced is related to many different areas such as commerce, tourism, education, health and causes the size of the Social Web to expand exponentially.
Mining opinions and sentiments from natural language involves a deep understanding of most of the explicit and implicit, regular and irregular, syntactical and semantic rules proper of a language.
Existing approaches are mainly focused on the identification of parts of the text where opinions and sentiments can be explicitly expressed such as polarity terms, expressions, affect words. They usually adopt purely syntactical approaches and are heavily dependent on the source language of the input text. They miss many language patterns where opinions can be expressed though.
Understanding the semantics of a sentence offers an exciting research opportunity and challenge to the Semantic Web community as well. In fact, the Semantic Sentiment Analysis Challenge aims to go beyond a mere word-level analysis of text and provides novel methods to opinion mining and analysis that can transform more efficiently unstructured textual information to structured machine-processable data.
By relying on Semantic Web best practices and techniques, fine-grained sentiment analysis relies on the implicit features associated with natural language concepts. Unlike purely syntactical techniques, semantic sentiment analysis approaches are able to detect also sentiments that are implicitly expressed within the text.
Website: https://github.com/diegoref/SSA2016
6th Open Challenge on Question Answering over Linked Data (QALD-6)
The past years have seen a growing amount of research on question answering over Semantic Web data, shaping an interaction paradigm that allows end users to profit from the expressive power of Semantic Web standards while at the same time hiding their complexity behind an intuitive and easy-to-use interface. The Question Answering over Linked Data challenge provides an up-to-date benchmark for assessing and comparing systems that mediate between a user, expressing his or her information need in natural language, and RDF data. It thus targets all researchers and practitioners working on querying linked data, natural language processing for question answering, multilingual information retrieval and related topics.
The key challenge for question answering over linked data is to translate a user’s information need into a form such that it can be evaluated using standard Semantic Web query processing and inferencing techniques. In order to focus on specific aspects and involved challenges, QALD comprises three tasks: multilingual question answering over DBpedia, hybrid question answering over both RDF and free text data, and question answering over statistical data in RDF data cubes.
Website: http://www.sc.cit-ec.uni-bielefeld.de/qald
Top-K Shortest Path in Large Typed RDF Graphs Challenge
The advent of SPARQL 1.1 introduced property paths as a new graph matching paradigm that allows the employment of Kleene star * (and it's variant +) unary operators to build SPARQL queries that are agnostic of the underlying RDF graph structure. The ability to express path patterns that are agnostic of the underlying graph structure is certainly a step forward. Still though, it is impossible to retrieve the actual paths through a property path sparql query. In this challenge, we ask for a system capable of returning the actual paths between two URIs in a RDF graph ranked by their length. This is of evident interest for big data approaches, because it enlarges the scope for picking up tuples / data while concurrently establishing a route between them that may be interpreted in different ways.
Website: https://bitbucket.org/ipapadakis/eswc2016-challenge
Semantic Publishing Challenge 2016 – Assessing the Quality of Scientific Output in its Ecosystem
The 3rd edition of the Semantic Publishing Challenge continues pursuing the objective of assessing the quality of scientific output, evolving the dataset bootstrapped in 2014 and continued in 2015. This year’s edition has the same structure of SemPub 2015 with some improvements, to reach a wider ecosystem of publications. Participants are invited to submit new approaches or to refine and enrich the solutions produced in the past. This edition looks into (i) extracting deeper information from the HTML and PDF sources of the workshop proceedings volumes and enriching this information with knowledge from existing datasets; (ii) interlinking the output of Task 1 and 2, as well as the CEUR-WS dataset to other datasets. Thus, a combination of broadly investigated technologies, such as Information Extraction, Natural Language Processing, Named Entity Recognition, Instance Matching, Link Discovery, etc., is required to deal with the challenge’s tasks. Participants will submit their dataset along with standard-conforming SPARQL queries against the dataset, and CSV-formatted query results. We will measure the extent to which the submitted dataset refines the CEUR-WS dataset by determining the precision and recall of predefined evaluation queries. Last, the existence of provenance information of the submitted dataset will be promoted.
Website: https://github.com/ceurws/lod/wiki/SemPub2016